

language:
- en
- zh
library_name: transformers
license: mit
pipeline_tag: text-generation
GLM-4.7
👋 Join our Discord community.
📖 Check out the GLM-4.7 technical blog, technical report(GLM-4.5).
📍 Use GLM-4.7 API services on Z.ai API Platform.
👉 One click to GLM-4.7.
Introduction
GLM-4.7, your new coding partner, is coming with the following features:
- Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +10.0%) on Terminal Bench. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
- Vibe Coding: GLM-4.7 takes a major step forward in UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
- Tool Using: Tool using is significantly improved. GLM-4.7 achieves open-source SOTA results on multi-step tool using benchmarks such as τ^2-Bench and on web browsing via BrowserComp.
- Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
More general, one would also witness significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
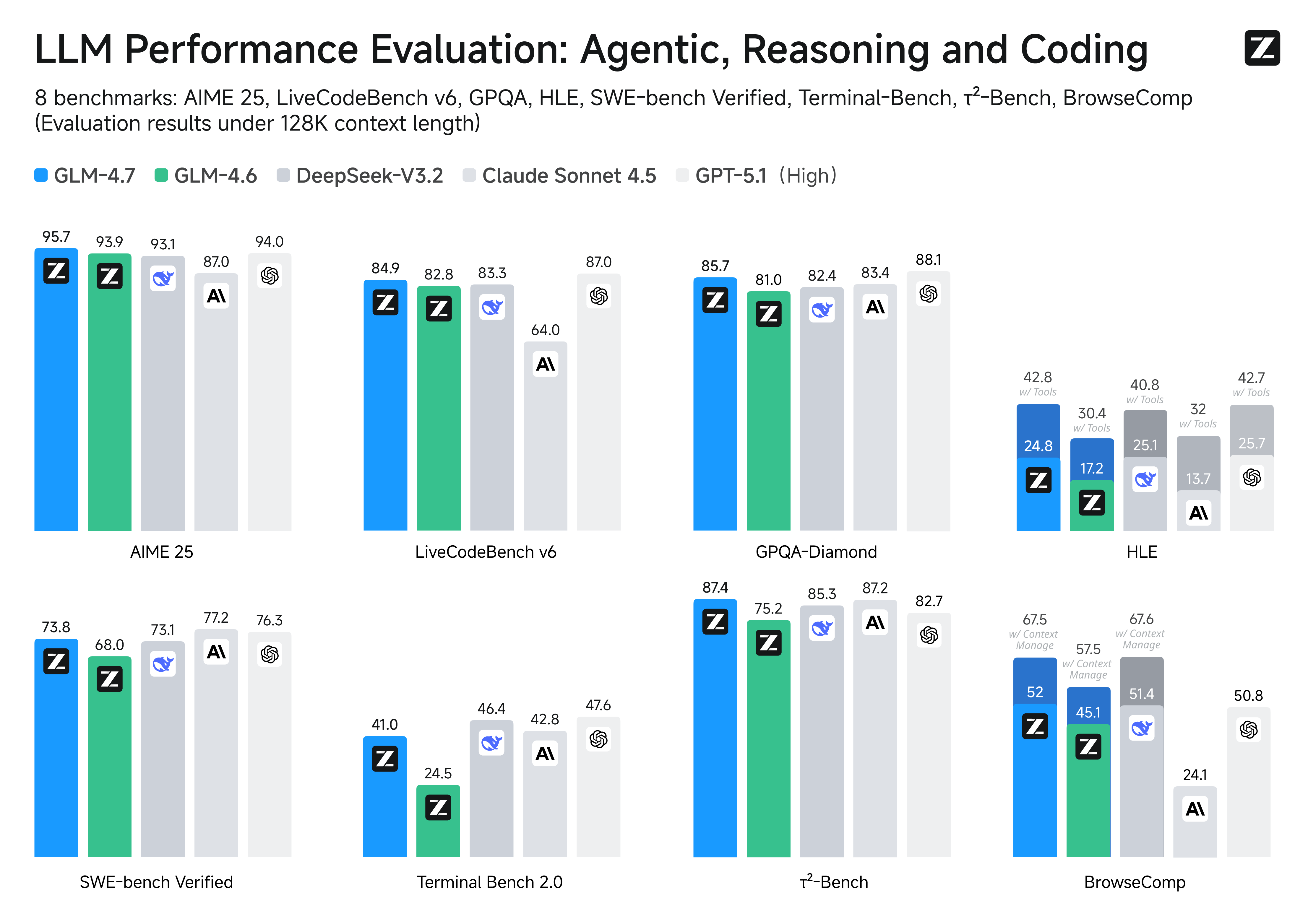
Benchmark
| Benchmark | GLM-4.7 | GLM-4.6 | MiMo-V2-Flash | Kimi-K2-Thinking | DeepSeek-V3.2 | Gemini-3.0-Pro | Claude-Sonnet-4.5 | GPT-5-High | GPT-5.1-High | GPT-5.2-High |
|---|---|---|---|---|---|---|---|---|---|---|
| MMLU-Pro | 84.3 | 83.2 | 84.9 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 | 87.0 | 87.0 |
| GPQA-Diamond | 85.7 | 81.0 | 83.7 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 | 88.1 | 92.4 |
| HLE | 24.8 | 17.2 | 22.1 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 | 25.7 | 34.5 |
| HLE (w/ Tools) | 42.8 | 30.4 | - | 44.9 | 40.8 | 45.8 | 32.0 | 35.2 | 42.7 | 45.5 |
| AIME 2025 | 95.7 | 93.9 | 94.1 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 | 94.0 | 100.0 |
| HMMT Feb. 2025 | 97.1 | 89.2 | 84.4 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 | 96.3 | 99.4 |
| HMMT Nov. 2025 | 93.5 | 87.7 | - | 89.2 | 90.2 | 93.3 | 81.7 | 89.2 | - | - |
| IMOAnswerBench | 82.0 | 73.5 | - | 78.6 | 78.3 | 83.3 | 65.8 | 76.0 | - | - |
| LiveCodeBench-v6 | 84.9 | 82.8 | 80.6 | 83.1 | 83.3 | 90.7 | 64.0 | 87.0 | 87.0 | - |
| SWE-Bench Verified | 73.8 | 68.0 | 73.4 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 | 76.3 | 80.0 |
| SWE-Bench Multilingual | 66.7 | 53.8 | 71.7 | 61.1 | 70.2 | - | 68.0 | 55.3 | - | - |
| Terminal Bench Hard | 33.3 | 23.6 | 30.5 | 30.6 | 35.4 / 33 | 39.0 | 33.3 | 30.5 | 43.0 | - |
| Terminal Bench 2.0 | 41.0 | 24.5 | 38.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 | 47.6 | 54.0 |
| BrowseComp | 52.0 | 45.1 | 45.4 | - | 51.4 | - | 24.1 | 54.9 | 50.8 | 65.8 |
| BrowseComp (w/ Context Manage) | 67.5 | 57.5 | 58.3 | 60.2 | 67.6 | 59.2 | - | - | - | - |
| BrowseComp-Zh | 66.6 | 49.5 | - | 62.3 | 65.0 | - | 42.4 | 63.0 | - | - |
| τ²-Bench | 87.4 | 75.2 | 80.3 | 74.3 | 85.3 | 90.7 | 87.2 | 82.4 | 82.7 | - |
Evaluation Parameters
Default Settings (Most Tasks)
- temperature:
1.0 - top-p:
0.95 - max new tokens:
131072
For agentic tasks, please turn on Preserved Thinking mode.
Terminal Bench, SWE Bench Verified
- temperature:
0.7 - top-p:
1.0 - max new tokens:
16384
τ^2-Bench
- Temperature:
0 - Max new tokens:
16384
For τ^2-Bench evaluation, we added an additional prompt to the Retail and Telecom user interaction to avoid failure modes caused by users ending the interaction incorrectly. For the Airline domain, we applied the domain fixes as proposed in the Claude Opus 4.5 release report.
Inference
Check our Github For More Detail.