

library_name: transformers
license: mit
pipeline_tag: text-generation
tags:
- DeepSeek-R1-0528
- GPTQ
- Int4-Int8Mix
- 量化修复
- vLLM
base_model:
- deepseek-ai/DeepSeek-R1-0528
base_model_relation: quantized
DeepSeek-R1-0528-GPTQ-Int4-Int8Mix-Medium
基础型 deepseek-ai/DeepSeek-R1-0528
本仓库提供一份 Int4 + 混合Int8 的 GPTQ 模型:仅将对量化敏感的层保留为 Int8,其余维持 Int4,以尽可能小的体积保有模型的生成质量。
初步试验表明,若直接按 vLLM 默认布局将模型整体转换为纯 Int4(AWQ/GPTQ),推理精度不足,可能导致输出异常。按层精细量化可以显著缓解这一问题。
临时补丁:
vLLM == 0.9.0 目前尚未原生支持 MoE 模块的逐层量化。
我们在 gptq_marlin.py 中增补了 get_moe_quant_method 以作过渡。
在官方 PR 合并之前,请先用随仓库附带的文件替换原文件。
版本选择一览
| 版本 | 特点 | 文件大小 | 适用场景 |
|---|---|---|---|
| Lite | 仅将最必要的层提升至 Int8,体积接近纯 Int4 | 355 GB | 资源受限、轻量化的服务器部署环境 |
| Compact | Int8 层更多,精度更高 | 414 GB | 显存较为充裕、对作答质量要求高(例如 8xA800) |
| Medium | Compact基础上,注意力层全数Int8,精度高、长文损失小 | 445 GB | 显存充裕、追求作答质量与并发能力的均衡(例如 8xH20) |
请根据硬件条件与精度需求选择合适版本。
【模型更新日期】
2025-06-04
1. 首次commit
【依赖】
vllm==0.9.0
transformers==4.52.3
目前 vllm==0.9.0 对于moe模块的逐层量化设置没有实现出来,会导致模型加载错误。
我这边简易实现了一下,即在 gptq_marlin.py 文件中补充 get_moe_quant_method 函数。
在pr merge之前,请先将附件中的gptq_marlin.py文件替换至
.../site-packages/vllm/model_executor/layers/quantization/gptq_marlin.py
【模型列表】
| 文件大小 | 最近更新时间 |
|---|---|
445GB |
2025-06-04 |
【模型下载】
from modelscope import snapshot_download
snapshot_download('tclf90/DeepSeek-R1-0528-GPTQ-Int4-Int8Mix-Medium', cache_dir="本地路径")
【介绍】
DeepSeek-R1-0528

1. Introduction
The DeepSeek R1 model has undergone a minor version upgrade, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
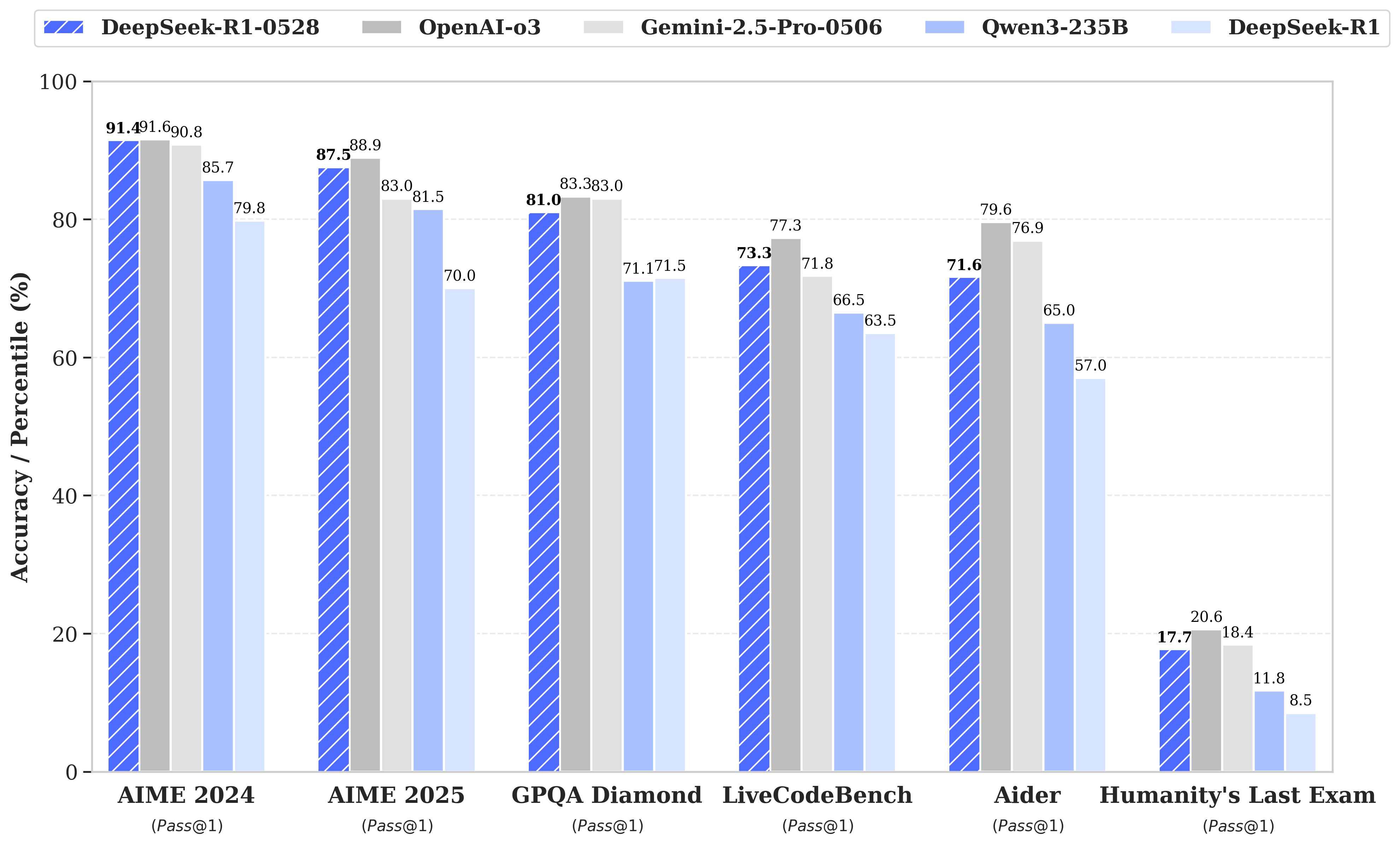
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
2. Evaluation Results
DeepSeek-R1-0528
For all our models, the maximum generation length is set to 64K tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 16 responses per query to estimate pass@1.
| Category | Benchmark (Metric) | DeepSeek R1 | DeepSeek R1 0528 |
|---|---|---|---|
| General | |||
| MMLU-Redux (EM) | 92.9 | 93.4 | |
| MMLU-Pro (EM) | 84.0 | 85.0 | |
| GPQA-Diamond (Pass@1) | 71.5 | 81.0 | |
| SimpleQA (Correct) | 30.1 | 27.8 | |
| FRAMES (Acc.) | 82.5 | 83.0 | |
| Humanity's Last Exam (Pass@1) | 8.5 | 17.7 | |
| Code | |||
| LiveCodeBench (2408-2505) (Pass@1) | 63.5 | 73.3 | |
| Codeforces-Div1 (Rating) | 1530 | 1930 | |
| SWE Verified (Resolved) | 49.2 | 57.6 | |
| Aider-Polyglot (Acc.) | 53.3 | 71.6 | |
| Math | |||
| AIME 2024 (Pass@1) | 79.8 | 91.4 | |
| AIME 2025 (Pass@1) | 70.0 | 87.5 | |
| HMMT 2025 (Pass@1) | 41.7 | 79.4 | |
| CNMO 2024 (Pass@1) | 78.8 | 86.9 | |
| Tools | |||
| BFCL_v3_MultiTurn (Acc) | - | 37.0 | |
| Tau-Bench (Pass@1) | - | 53.5(Airline)/63.9(Retail) |
5. License
This code repository is licensed under MIT License. The use of DeepSeek-R1 models is also subject to MIT License. DeepSeek-R1 series (including Base and Chat) supports commercial use and distillation.
6. Citation
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
7. Contact
If you have any questions, please raise an issue or contact us at [email protected].