
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,143 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- yolay/SmartSnap-FT
|
| 5 |
+
- yolay/SmartSnap-RL
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
metrics:
|
| 9 |
+
- accuracy
|
| 10 |
+
base_model:
|
| 11 |
+
- meta-llama/Llama-3.1-8B-Instruct
|
| 12 |
+
tags:
|
| 13 |
+
- agent
|
| 14 |
+
- mobile
|
| 15 |
+
- gui
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
<div align="center">
|
| 22 |
+
<img src="https://raw.githubusercontent.com/yuleiqin/images/master/SmartSnap/mascot_smartsnap.png" width="400"/>
|
| 23 |
+
</div>
|
| 24 |
+
|
| 25 |
+
<p align="center">
|
| 26 |
+
<a href="https://arxiv.org/abs/tobeonline">
|
| 27 |
+
<img src="https://img.shields.io/badge/arXiv-Paper-red?style=flat-square&logo=arxiv" alt="arXiv Paper"></a>
|
| 28 |
+
|
| 29 |
+
</p>
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
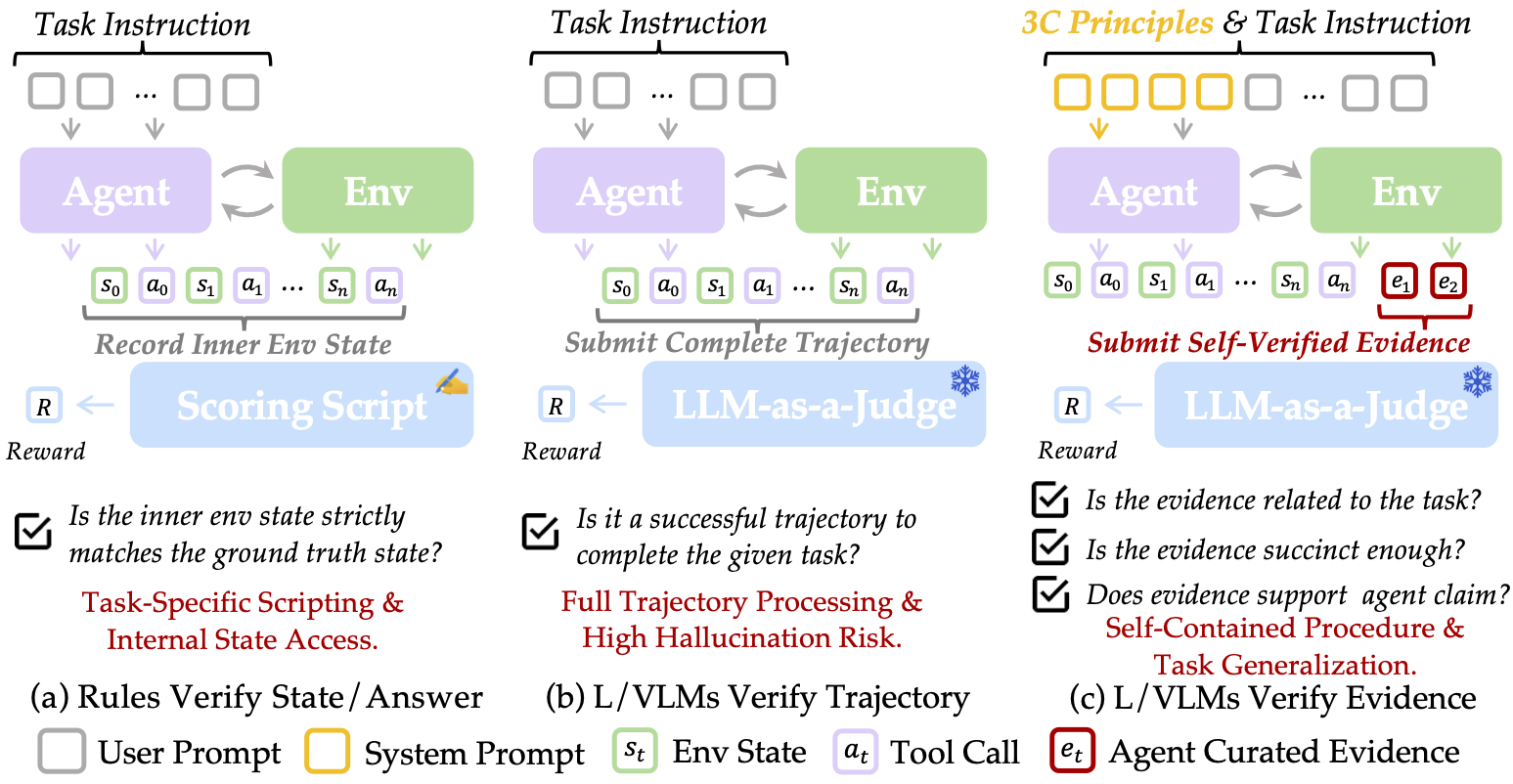
We introduce **SmartSnap**, a paradigm shift that transforms GUI agents📱💻🤖 from passive task executors into proactive self-verifiers. By empowering agents to curate their own evidence of success through the **3C Principles** (Completeness, Conciseness, Creativity), we eliminate the bottleneck of expensive post-hoc verification while boosting reliability and performance on complex mobile tasks.
|
| 33 |
+
|
| 34 |
+
# 📖 Overview
|
| 35 |
+
|
| 36 |
+
SmartSnap redefines the agent's role through a unified policy that handles both **task execution** and **evidence curation**. Instead of burdening verifiers with verbose, noisy interaction trajectories, agents learn to select minimal, decisive snapshot evidences from their tool interactions. The framework leverages:
|
| 37 |
+
|
| 38 |
+
- **Augmented MDP**: Agents operate in an extended action space ⊕ consisting of execution actions (click, type, etc.) and curation actions (submit evidence indices)
|
| 39 |
+
- **Dual-objective training**: GRPO-based RL optimizes for both task completion and evidence quality
|
| 40 |
+
- **Dense reward shaping**: Multi-component rewards $R_{format}$ + $R_{validity}$ + $R_{complete}$ + $R_{concise}$ guide agents toward becoming effective self-verifiers
|
| 41 |
+
- **Creative evidence generation**: Agents proactively execute additional actions post-task to capture robust proof when needed
|
| 42 |
+
|
| 43 |
+
The approach achieves up to **26.08% absolute performance gains** on AndroidLab across model scales, matching or exceeding much larger models like DeepSeek-V3.1 and Qwen3-235B-A22B.
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# 📦 Releasing Contents
|
| 50 |
+
|
| 51 |
+
We release the following resources to accelerate research in self-verifying agents:
|
| 52 |
+
|
| 53 |
+
1. **Model Checkpoints** (HuggingFace Hub):
|
| 54 |
+
- `SmartSnap-Llama3.1-8B-Instruct` - RL-trained with 31.15% SR
|
| 55 |
+
- `SmartSnap-Qwen2.5-7B-Instruct` - RL-trained with 30.43% SR
|
| 56 |
+
- `SmartSnap-Qwen3-8B-Instruct` - RL-trained with 36.23% SR
|
| 57 |
+
- `SmartSnap-Qwen3-32B-Instruct` - RL-trained with 34.78% SR
|
| 58 |
+
- Corresponding SFT checkpoints for each model family
|
| 59 |
+
|
| 60 |
+
2. **Training Dataset**:
|
| 61 |
+
- 550K+ QA pairs from 30K+ curated trajectories on AndroidLab
|
| 62 |
+
- Evidence annotations following the 3C Principles
|
| 63 |
+
- XML-based environment observations and tool interaction logs
|
| 64 |
+
|
| 65 |
+
3. **Evaluation Suite**:
|
| 66 |
+
- AndroidLab benchmark integration (138 validation tasks across 9 apps)
|
| 67 |
+
- LLM-as-a-Judge evaluation pipeline (GLM4-based)
|
| 68 |
+
- Verifier implementation using DeepSeek-R1 with majority voting
|
| 69 |
+
|
| 70 |
+
4. **System Prompts**:
|
| 71 |
+
- Agent system prompt (~4K tokens) encoding the 3C Principles
|
| 72 |
+
- Verifier instructions for structured evidence assessment
|
| 73 |
+
- Reward shaping configuration files
|
| 74 |
+
|
| 75 |
+
# 💡 Key take-home Messages
|
| 76 |
+
|
| 77 |
+
- **Synergistic learning loop**: The dual mission of executing and verifying cultivates deeper task understanding—agents learn to decompose problems into evidence milestones, implicitly improving planning capabilities.
|
| 78 |
+
|
| 79 |
+
- **Evidence quality matters**: Vanilla SFT only achieves ~22% SR across models, while self-verifying SFT reaches 23-30% SR, demonstrating that evidence curation training is more effective than solution memorization.
|
| 80 |
+
|
| 81 |
+
- **RL unlocks generalization**: Fine-tuned models show consistent >16% absolute gains after RL training, with smaller models (8B) outperforming their naive prompting baselines by **26.08%**.
|
| 82 |
+
|
| 83 |
+
- **Efficiency through conciseness**: Trained agents converge to submitting **~1.5 evidence snapshots** on average, drastically reducing verifier costs while maintaining high reliability.
|
| 84 |
+
|
| 85 |
+
- **Limitations**: Tasks requiring extensive domain knowledge (e.g., Maps.me navigation) remain challenging without explicit knowledge injection, suggesting RL alone cannot bridge large knowledge gaps.
|
| 86 |
+
|
| 87 |
+
# 📊 Experimental Results
|
| 88 |
+
|
| 89 |
+
| Type | Model | SR | Sub-SR | RRR | ROR |
|
| 90 |
+
|------|-------|----|--------|-----|-----|
|
| 91 |
+
| **PT** | GPT-4o | 25.36 | 30.56 | **107.45** | 86.56 |
|
| 92 |
+
| **PT** | GPT-4-1106-Preview | 31.16 | 38.21 | 66.34 | 86.24 |
|
| 93 |
+
| **PT** | Gemini-1.5-Pro | 18.84 | 22.40 | 57.72 | 83.99 |
|
| 94 |
+
| **PT** | Gemini-1.00 | 8.70 | 10.75 | 51.80 | 71.08 |
|
| 95 |
+
| **PT** | GLM4-Plus | 27.54 | 32.08 | 92.35 | 83.41 |
|
| 96 |
+
| **PT** | DeepSeek-V3.1 | **36.23** | <u>40.95</u> | 81.01 | 94.63 |
|
| 97 |
+
| **PT** | Qwen3-235B-A22B | <u>34.78</u> | 38.76 | 83.35 | 89.48 |
|
| 98 |
+
| | **Act-only**<sup>*</sup> | | | | |
|
| 99 |
+
| **PT** | LLaMA3.1-8B-Instruct<sup>‡</sup> | 2.17 | 3.62 | — | 52.77 |
|
| 100 |
+
| **FT**<sup>†</sup> | LLaMA3.1-8B-Instruct<sup>‡</sup> | 23.91<sup>(+21.74%)</sup> | 30.31 | 75.58 | 92.46 |
|
| 101 |
+
| **PT** | LLaMA3.1-8B-Instruct | 5.07 | 6.28 | 52.77 | 51.82 |
|
| 102 |
+
| **FT**<sup>†</sup> | LLaMA3.1-8B-Instruct | 20.28<sup>(+15.21%)</sup> | 26.13 | 69.44 | 90.43 |
|
| 103 |
+
| **FT (ours)** | LLaMA3.1-8B-Instruct | 23.91<sup>(+18.84%)</sup> | 30.36 | 37.96 | 83.23 |
|
| 104 |
+
| **RL (ours)** | LLaMA3.1-8B-Instruct | 31.15<sup>(+26.08%)</sup> | 38.03 | 81.28 | <u>95.80</u> |
|
| 105 |
+
| | **ReAct** | | | | |
|
| 106 |
+
| **PT** | Qwen2.5-7B-Instruct | 12.32 | 14.98 | 67.56 | 78.52 |
|
| 107 |
+
| **FT**<sup>†</sup> | Qwen2.5-7B-Instruct | 20.28<sup>(+7.96%)</sup> | 27.05 | 35.52 | 62.46 |
|
| 108 |
+
| **FT (ours)** | Qwen2.5-7B-Instruct | 30.15<sup>(+17.83%)</sup> | 36.59 | 49.19 | 73.28 |
|
| 109 |
+
| **RL (ours)** | Qwen2.5-7B-Instruct | 30.43<sup>(+18.11%)</sup> | 35.20 | <u>102.30</u> | **96.36** |
|
| 110 |
+
| **PT** | Qwen3-8B-Instruct | 10.14 | 12.38 | 66.21 | 67.15 |
|
| 111 |
+
| **FT**<sup>†</sup> | Qwen3-8B-Instruct | 19.56<sup>(+9.41%)</sup> | 25.60 | 38.69 | 65.18 |
|
| 112 |
+
| **FT (ours)** | Qwen3-8B-Instruct | 26.81<sup>(+16.66%)</sup> | 31.09 | 72.16 | 69.85 |
|
| 113 |
+
| **RL (ours)** | Qwen3-8B-Instruct | **36.23**<sup>(+26.08%)</sup> | **41.96** | 88.04 | 94.49 |
|
| 114 |
+
| **PT** | Qwen3-32B-Instruct | 18.12 | 21.80 | 91.99 | 87.57 |
|
| 115 |
+
| **FT**<sup>†</sup> | Qwen3-32B-Instruct | 22.46<sup>(+4.34%)</sup> | 28.20 | 39.28 | 65.50 |
|
| 116 |
+
| **FT (ours)** | Qwen3-32B-Instruct | 28.98<sup>(+10.86%)</sup> | 35.92 | 97.79 | 97.33 |
|
| 117 |
+
| **RL (ours)** | Qwen3-32B-Instruct | <u>34.78</u><sup>(+16.66%)</sup> | 40.26 | 89.47 | 93.67 |
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
*<sup>*</sup> LLaMA3.1 models only natively support tool calling w/o reasoning.*
|
| 122 |
+
*<sup>†</sup> The Android Instruct dataset is used for fine-tuning where self-verification is not performed.*
|
| 123 |
+
*<sup>‡</sup> The official results are cited here for comparison.*
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
---
|
| 127 |
+
|
| 128 |
+
- **Performance gains**: All model families achieve >16% improvement over prompting baselines, reaching competitive performance with models 10-30× larger.
|
| 129 |
+
- **RL dynamics**: Training reward increases consistently while intra-group variance decreases, indicating stable convergence despite occasional performance fluctuations in complex domains (Calendar, Zoom).
|
| 130 |
+
- **App-specific analysis**: Dominant improvement in Settings (31% of training tasks) validates the importance of balanced task distribution.
|
| 131 |
+
|
| 132 |
+
# 📝 Citation
|
| 133 |
+
|
| 134 |
+
If you use SmartSnap in your research, please cite:
|
| 135 |
+
|
| 136 |
+
```bibtex
|
| 137 |
+
@article{smartsnap2025,
|
| 138 |
+
title={SmartSnap: Proactive Self-Verification for Scalable GUI Agent Training},
|
| 139 |
+
author={Shaofei Cai and Yulei Qin and Haojia Lin and Zihan Xu and Gang Li and Yuchen Shi and Zongyi Li and Yong Mao and Siqi Cai and Xiaoyu Tan and Yitao Liang and Ke Li and Xing Sun},
|
| 140 |
+
journal={arXiv preprint arXiv:2025},
|
| 141 |
+
year={2025}
|
| 142 |
+
}
|
| 143 |
+
```
|