Datasets:


license: cc-by-4.0
task_categories:
- text-generation
language:
- ja
tags:
- synthetic
- personas
- NVIDIA
size_categories:
- 1M<n<10M
Nemotron-Personas-Japan
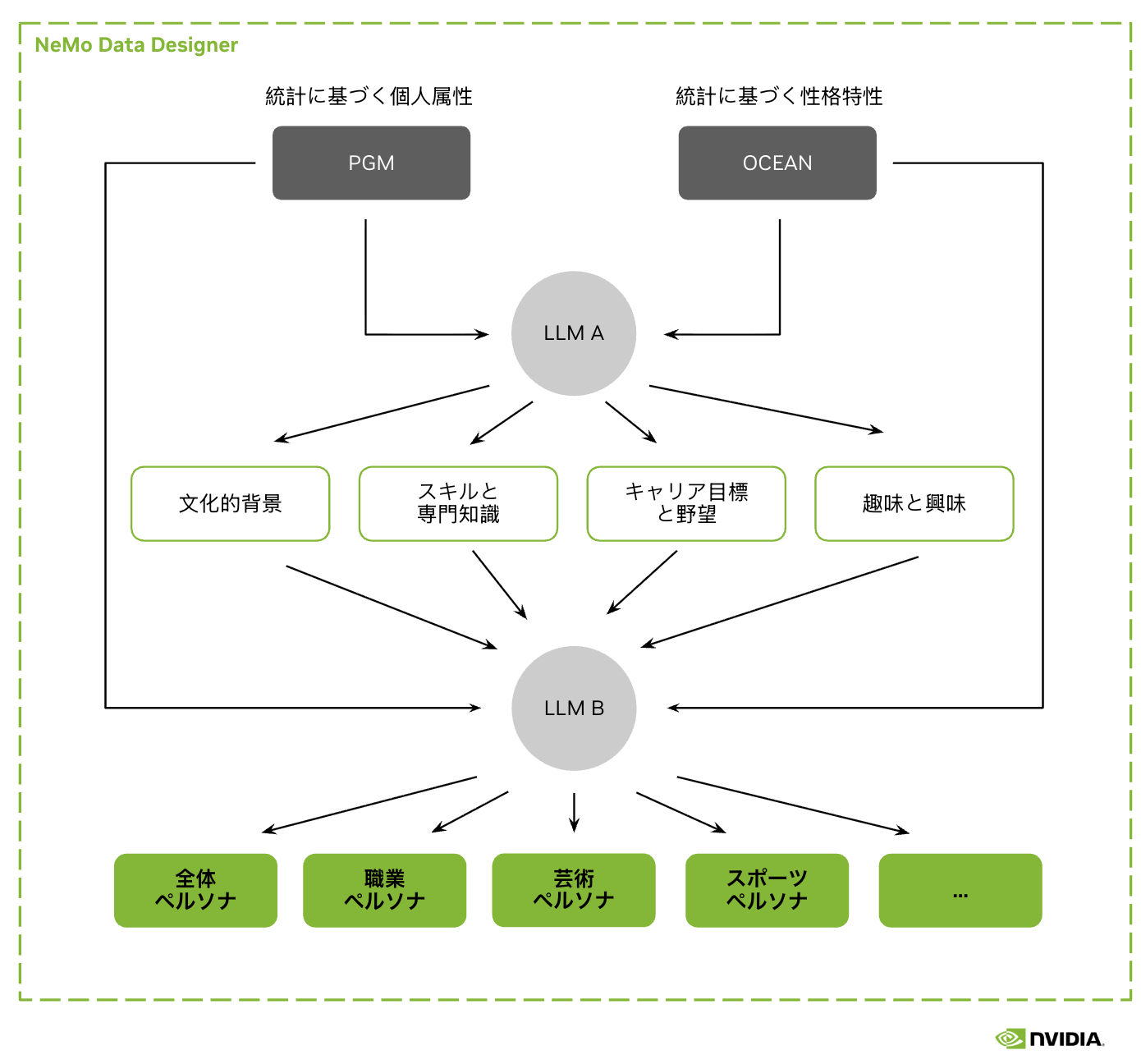
現実世界の分布に基づいたペルソナ生成のための複合AIアプローチ
データセット概要 (Dataset Overview)
Nemotron-Personas-Japan は、日本における人口の多様性と豊かさを捉えることを目的とし、実世界の人口統計、地理的分布、性格特性の分布に基づいて合成的に生成されたペルソナのオープンソースデータセットです。名前、性別、年齢、背景、婚姻状況、学歴、職業、居住地などの統計に基づいて生成した初のデータセットされた Nemotron-Personas の日本語版です。本バージョンでは、日本語における多様なモデリングユースケースに適した高品質のペルソナを提供します
Nemotron-Personas-Japan は、日本のモデル開発者が重要な地域固有の人口統計や文化的背景を取り入れたソブリンAIシステムを開発することを支援します。本データセットは、日本の地理的・人口統計的な実分布を反映することで、合成データの多様性を高め、バイアスを軽減し、model collapse(他モデルの出力を無条件に学習することで生じる劣化)を防ぎます。特に、過去のペルソナデータセットと比較して、年齢(例:高齢者ペルソナ)、地理(例:地方在住ペルソナ)、学歴、職業など、複数の軸で人口統計的分布をより代表するように設計されています。例えば、実際の名前、年齢、職業、文化的・教育的背景を含んだ高品質なマルチターン会話データを生成でき、そのデータにユニークな視点や切り口をもたらします。
本データセットは、合成データ生成のためのエンタープライズ向け複合AIシステム NeMo Data Designer を用いて作成されました。独自の確率的グラフィカルモデル(PGM)、Apache-2.0 ライセンスの GPT-OSS-120B モデル、さらに Data Designer に組み込まれた拡張可能なバリデータや評価器群を活用しています。拡張版の Nemotron-Personas-Japan は、まもなく NeMo Data Designer 上で直接利用可能になります。
本データセットは商用利用可能です。
Nemotron-Personas-Japan is an open-source (CC BY 4.0) dataset of synthetically-generated personas grounded in real-world demographic, geographic, and personality trait distributions in Japan to capture the diversity and richness of the population. It is a variant of Nemotron-Personas, which is the first dataset of its kind aligned with statistics for names, sex, age, background, marital status, education, occupation and location, among other attributes. This version of the dataset provides high-quality personas for a variety of modeling use-cases in Japanese.
Nemotron-Personas-Japan supports Japanese model builders in developing Sovereign AI systems that incorporate important region-specific demographics and cultural context. The dataset improves diversity of synthetically-generated data, mitigates biases, and prevents model collapse (degradation caused by uncurated training on another model's outputs) by reflecting Japan's real geographic and demographic distributions. In particular, the dataset is designed to be more representative of underlying demographic distributions along multiple axes, including age (e.g. older personas), geography (e.g., rural personas), education, occupation, etc., as compared to past persona datasets. As an example, one can produce high-quality multi-turn chat conversation data with real names, ages, occupation, cultural and education backgrounds, all of which bring unique perspectives and angles to that data.
Produced using NeMo Data Designer, an enterprise-grade compound AI system for synthetic data generation, the dataset leverages a proprietary Probabilistic Graphical Model (PGM) along with an Apache-2.0-licensed GPT-OSS-120B model and an ever-expanding set of validators and evaluators built into Data Designer. An extended version of Nemotron-Personas-Japan is available for use in NeMo Data Designer itself.
This dataset is ready for commercial use.
データセットに含まれないもの (What is NOT in the dataset)
ペルソナに重点を置いているため、本データセットには NeMo Data Designer で利用可能な他のフィールド(氏名や合成住所など)は含まれていません。また、企業向けクライアントに関連性の高いペルソナ(例:金融、医療)も除外されています。エンタープライズユースケースをご検討の場合は、ぜひこちらまでご連絡ください。
本データは実世界の分布を反映しているものの、完全に人工的に生成されたものです。氏名やペルソナ記述が実在の人物(生存・故人を問わず)に類似している場合でも、それは偶然の一致にすぎず、いかなる関連性も意図されておらず保証されるものではありません。
Given the emphasis on personas, the dataset excludes other fields available in NeMo Data Designer, e.g., first/last names and synthetic addresses. Also excluded are personas generally of relevance to enterprise clients (e.g., finance, healthcare). Please reach out to explore enterprise use-cases.
All data, while mirroring real-world distributions, is completely artificially generated. Any similarity in names or persona descriptions to actual persons, living or dead, is purely coincidental.
データセット作者 (Data Developer)
NVIDIA Corporation
リリース日 (Release Date):
09/23/2025
ライセンス (License/Terms of Use)
このデータセットはCreative Commons Attribution 4.0 International License (CC-BY-4.0)に基づいて提供されています。
This dataset is licensed under the Creative Commons Attribution 4.0 International License (CC BY 4.0).
ユースケース (Use Case)
Sovereign AIの開発、LLMのトレーニング、あるいは合成データの多様性向上、データ/モデルのバイアス軽減、model collapseの防止を目指す開発者
Developers working on Sovereign AI, training LLMs and/or looking to improve diversity of synthetically generated data, mitigate data/model biases, and prevent model collapse.
データバージョン (Data Version)
1.0 (09/23/2025)
想定される利用方法 (Intended Use)
Nemotron-Personas-Japan データセット は、オープンモデルを継続的に改善し、最先端技術をさらに前進させるためにコミュニティで活用されることを目的としています。データはあらゆるモデルの学習に自由に利用することができます。私たちはオープンソースコミュニティからのフィードバックを歓迎するとともに、開発者、研究者、データ愛好者の皆様に本データセットを探求し、その上に新たな成果を築いていただくことを期待しています。
Nemotron-Personas-Japan データセットは、日本の国勢調査における自己申告の人口統計データ分布に基づいて構築されています。そのため、本データセットの主な目的は、既存のペルソナ・データセットを用いた合成データ生成において不足しているデータや潜在的なバイアスを補正し、ソブリンAIの開発を支援することにあります。日本の人口構成に忠実で多様性を高めたデータを提供しているものの、利用可能なデータの制約やモデルの合理的な複雑性により、限界が存在します。これにより、いくつかの独立性の仮定を設ける必要があります。例えば、職業は居住地(都道府県)および性別が与えられた場合、学歴とは独立していると仮定しています。同様に、日本の国勢調査からは、生物学的性別とは独立したジェンダーに関する包括的な統計は得られません。今後の課題として、データの忠実性をさらに高める取り組みに委ねています。
The Nemotron-Personas dataset is intended to be used by the community to continue to improve open models and push the state of the art. The data may be freely used to train any model. We welcome feedback from the open-source community and invite developers, researchers, and data enthusiasts to explore the dataset and build upon it.
The Nemotron-Personas-Japan dataset is grounded in distributions of self-reported demographic data in the Japanese census. As such, its primary goal is to support Sovereign AI development by combating missing data and/or potential biases present in model training data today, especially when it comes to existing persona datasets used in synthetic data generation. Despite the improved data diversity and fidelity to Japan's population, we are still limited by data availability and reasonable model complexity. This results in some necessary independence assumptions; for instance, that occupations are independent of education given location (prefecture) and sex. Similarly, comprehensive statistics on gender, independent of sex, are not available from the Japan Census. We leave further efforts to improve fidelity to future work.
Note that the dataset is focused on adults only.
データセット詳細 (Dataset Details)
本データセットには以下が含まれています。
- 日本語で記録された 100万件のレコード(1レコードあたり6つのペルソナ → 合計600万ペルソナ)
- 22フィールド:6つのペルソナフィールドと、公式の人口統計・労働統計に基づく16のコンテキストフィールド
- 約14億トークン数(うちペルソナ関連トークン約8.5億)
- 人口統計・地理・性格特性などの軸にまたがる包括的なデータ
- 約95万件のユニークな名前
- 日本の労働人口を反映する1,500以上の職業カテゴリ
- プロフェッショナル、スポーツ、芸術、旅行、料理など多様なペルソナタイプ
- 文化的背景、スキルと専門性、目標と志向、趣味や関心といった自然言語のペルソナ属性
Nemotron-Personas-Japan は、日本の公式人口統計および労働統計に整合させつつ、AI トレーニングにおいて重要な領域へ拡張することを目的に設計されました。具体的には次のような点を反映しています:
- 教育:国の統計では学位レベルが大きく分類されていますが、モデルが異なる教育経路を反映できるよう、より細分化を導入しました。
- 職業:自営業や専門職種などの追加カテゴリを取り入れ、学習に用いる職業スペクトラムを拡大しました。
- ライフステージ:統計上はあまり表に出ない学生、退職者、失業状態といったシナリオをモデリングし、より現実的なペルソナを表現できるようにしました。
- 文化的特性:日本の社会的・文化的特徴を組み込み、AI システムが地域固有の規範をより正確に反映できるようにしました。
- デジタルデバイド:年齢層ごとのデジタルリテラシーの差を考慮し、日本における実際のテクノロジー利用状況を反映しました。
これらの拡張は公共データという強固な基盤の上に構築されており、統計的に裏付けられ、文化的に代表性を持ちつつ、合成的でプライバシー保護され、かつオープンであるペルソナを創出することを可能にしています。
The dataset contains:
- 1M records in Japanese with 6 personas/record → 6M personas total
- 22 fields: 6 persona fields, and 16 contextual fields grounded in official demographic and labor statistics
- ~1.4B tokens total, including ~850M persona tokens
- Comprehensive coverage across demographic, geographic, and personality trait axes
- ~950k unique names
- 1500+ occupation categories reflecting Japan's workforce
- A variety of persona types: professional, sports, arts, travel, culinary
- Natural language persona attributes: cultural background, skills & expertise, goals & ambitions, hobbies & interests.
Nemotron-Personas-Japan was designed to align with Japan's official demographic and labor statistics, while extending them into areas important for AI training. In practice, this meant:
- Education: Where degree levels are grouped in national statistics, we introduced finer distinctions so models can reflect different educational pathways.
- Occupations: We incorporated additional categories (such as business owners and specialized trades) to broaden the occupational spectrum used in training.
- Life Stages: We included student, retirement, and unemployment status information which are important for realistic personas.
- Cultural Traits: To ensure authenticity, we included Japanese social and cultural characteristics that help AI systems better reflect local norms.
- Digital Divide: We accounted for different levels of digital literacy across age groups to reflect real-world technology usage patterns in Japan.
These extensions build on a strong foundation of public data, helping create personas that are both statistically grounded and culturally representative, while remaining synthetic, privacy-preserving, and open.
シードデータ (Seed Data)
日本の人口における社会人口学的および地理的な多様性と複雑性を捉えるために、Nemotron-Personas-Japan は以下の情報を利用しました:
In order to capture the socio-demographic and geographic diversity and complexity of Japan's population, Nemotron-Personas-Japan leveraged
- population census data published by the Statistics Bureau of Japan (e-Stat)
- name data provided by Myoji-Yurai.net (名字由来net) to reflect realistic first and last name distributions in Japan.
スキーマ (Schema)
本データセットには合計22のフィールドが含まれています。内訳は、ペルソナ関連フィールドが6つ、文脈関連フィールドが16つです。研究者にとって、多くの文脈関連フィールドは特定のペルソナを絞り込む際に有用であり、これは既存のデータセットでは困難とされてきた点です。

The dataset includes 22 fields: 6 persona fields and 16 contextual fields shown below. Researchers will find many contextual fields useful in zoning in on specific personas, which is challenging to do with existing datasets.

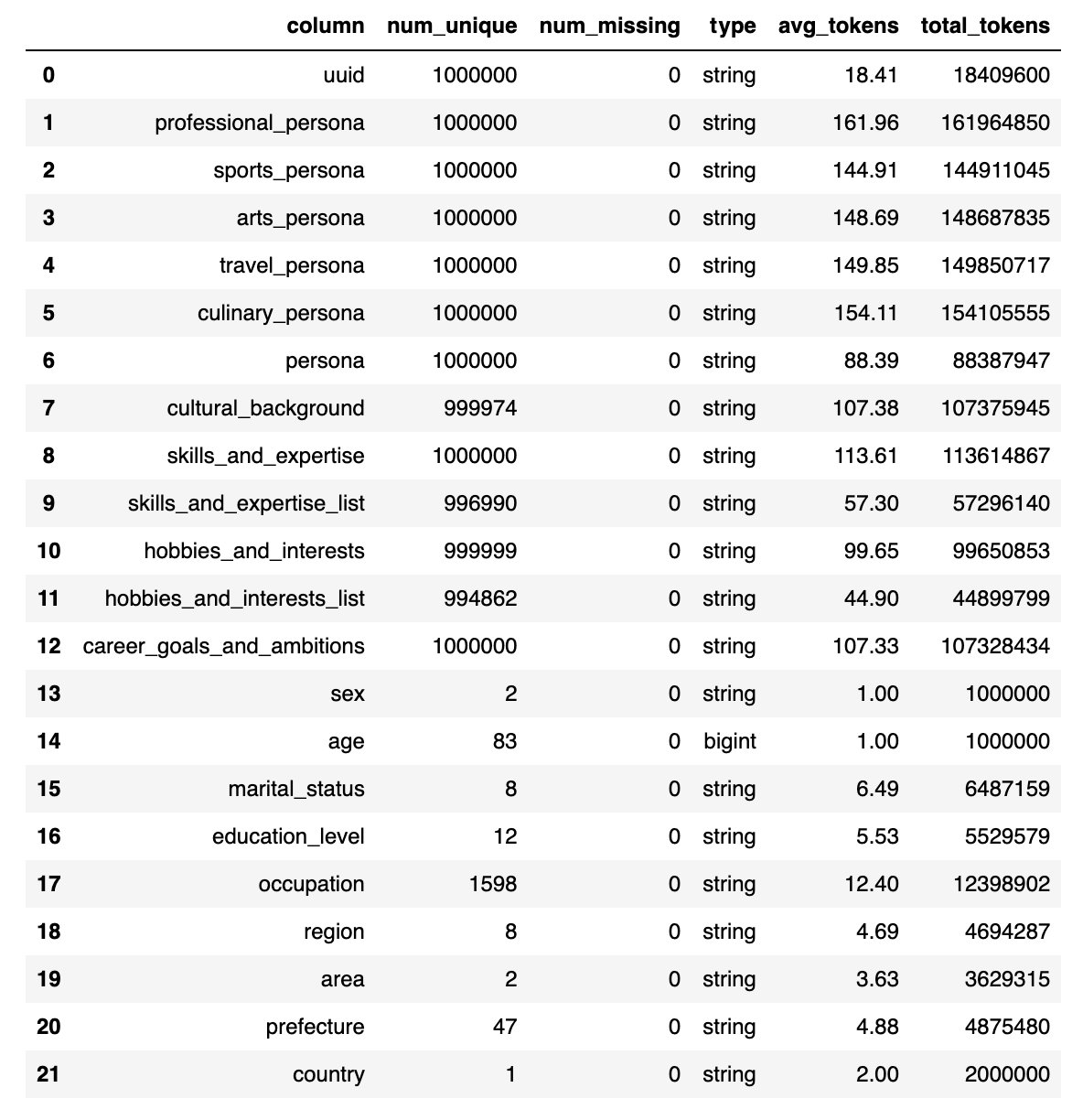
フィールド数&トークン数 (Field & Token Counts)
グローバルIDを除いて14億トークン(うち8.5億はペルソナトークン)、100万件のレコードと22カラムにわたり、。データは日本の47都道府県すべてを網羅しています。
1.4B tokens (850 persona tokens) across 1M records and 22 columns, excluding the globally unique identifier. Note that data covers all 47 prefectures in Japan.
データセット記述と品質評価 (Dataset Description & Quality Assessment)
以下、データセットの多様性とパターンの品質を確認するため、さまざまな観点からの分析を示しています。
The analysis below provides a breakdown across various axes of the dataset to emphasize the built-in diversity and pattern complexity of data.
氏名 (Names) 本データセットはペルソナに焦点を当てているため、氏名は専用のフィールドとしては提供されていません。しかし、ペルソナ合成には、名字由来net によって提供された 20,000 件のユニークな名前と 97,000 件のユニークな姓が組み込まれています。
Since the focus of this dataset is on personas, names aren't provided as dedicated fields. However, infused into persona generation are 20,000 unique first names, 97,000 unique last names provided by Myoji-Yurai.net.
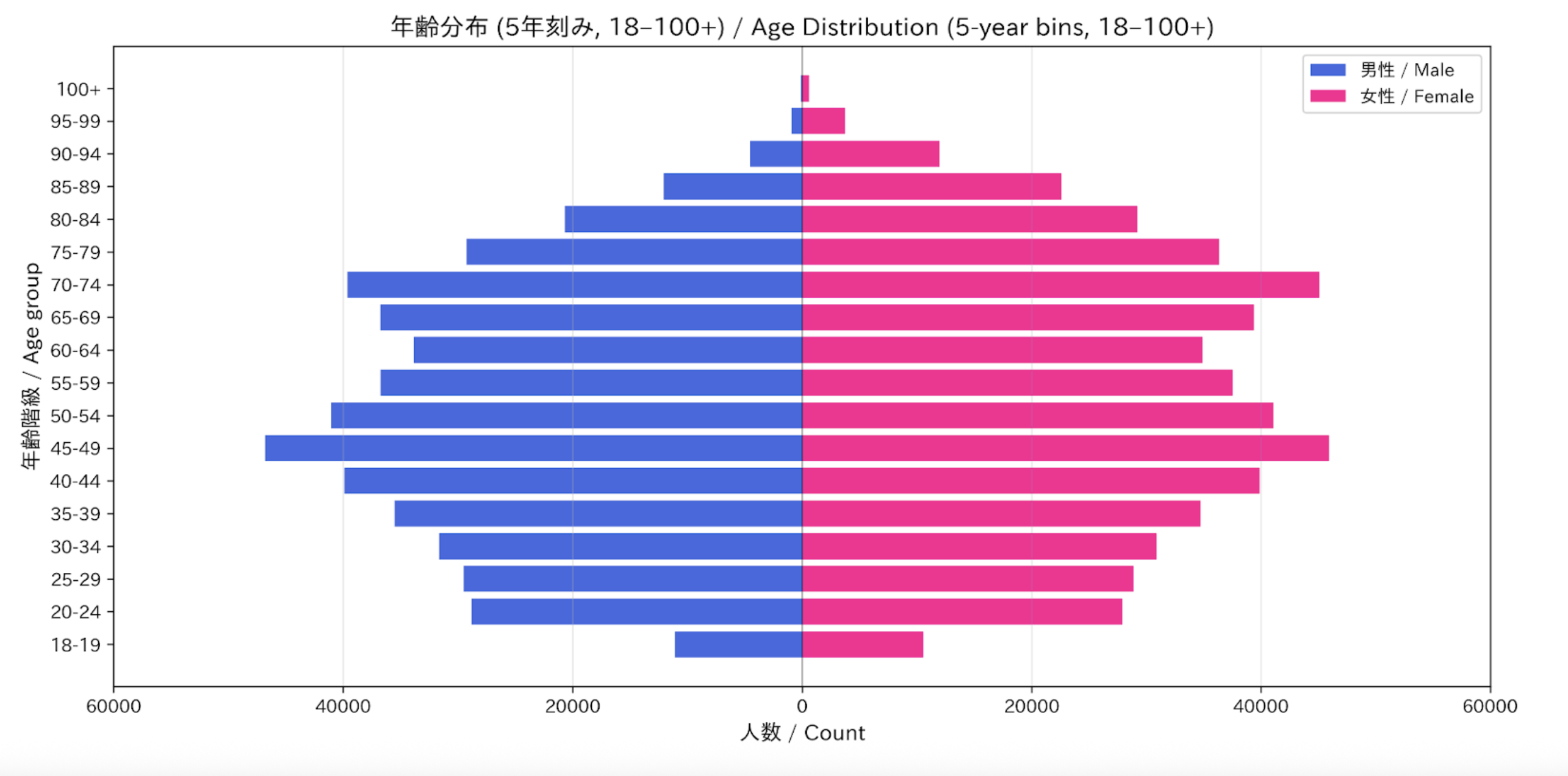
年齢分布 (Age Distribution)
日本のペルソナにおける年齢分布は、国全体の実際の人口構造を反映しており、中高年層が大きな割合を占め、若年層に向かって徐々に減少していくという特徴があります。この分布では若者が少なく、第一次および第二次ベビーブーム世代に大きな膨らみがあります。さらに、日本の女性は世界的に見ても非常に長寿であり、高齢者に占める女性の割合は高くなっています。
なお、このデータセットには 18 歳未満の未成年は含まれていません。
The age distribution of our Japanese personas mirrors the country's real demographic structure, characterized by a large proportion of people in the middle to older age groups and a gradual decline toward the younger cohorts. The distribution shows fewer young people and a significant expansion in the generations born during the baby boom and the second baby boom. Furthermore, Japanese women are exceptionally long-lived by global standards, and the proportion of women among the elderly is high.
Note that minors under 18 are excluded from this dataset.
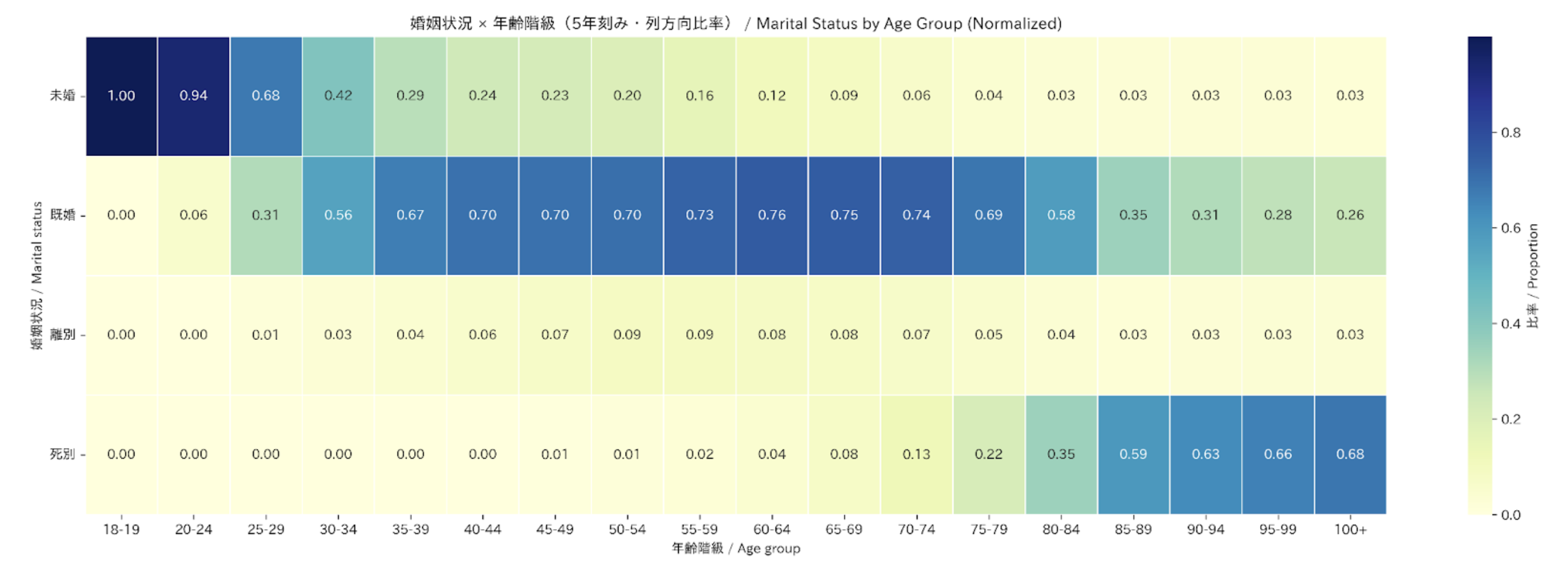
年齢層別の婚姻状況 (Marital Status by Age Group)
以下のヒートマップは、各年齢層における人々の割合を示しており、(1) 未婚、(2) 既婚、(3) 離婚、(4) 死別 の4つに分類しています。日本においては、人生の過程に沿って婚姻状況がどのように変化していくかが表れており、30代半ばまでは「未婚」が優勢ですが、その後「既婚」が徐々に増加し、「離婚」はほぼ横ばい、「死別」は高齢期に入って顕著になります。これらの要素はいずれも、日本のライフスタイルやペルソナを理解するうえで重要な示唆を与えます。
The heatmap below displays the fraction of people for each age cohort who are (1) never married, (2) currently married, (3) divorced, or (4) widowed. It highlights how marital status shifts over the life course in Japan, with “never married” dominating until mid 30s, when “married” start climbing gradually, “divorced” being flat, and “widowed” being much more pronounced in later life stages. All of these considerations are of relevance to informing life experiences and personas in Japan.
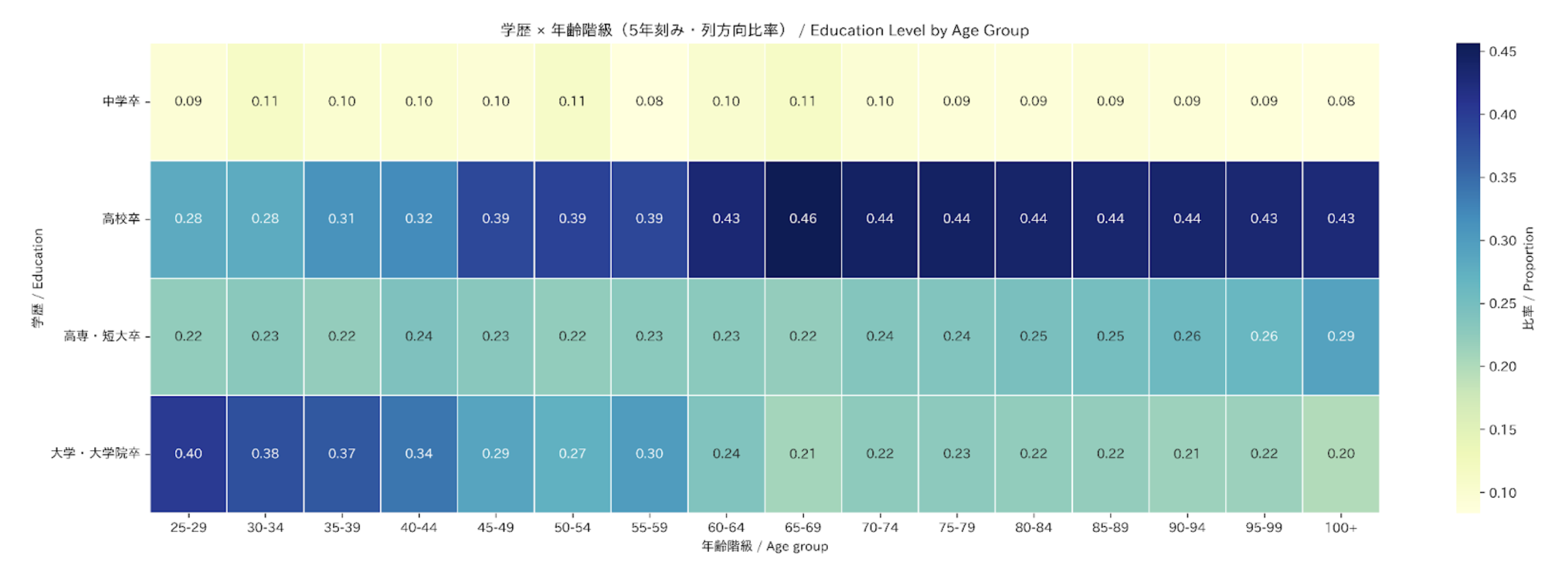
年齢層別の学歴水準 (Education Level by Age Group)
以下のヒートマップは、年齢層ごとの学歴達成のパターンを示しています。たとえば、学士号、修士号、博士号を取得している人の割合は、若い世代と高齢世代とで異なっており、教育機会へのアクセスや社会規範の歴史的な変化を反映しています。
The heatmap below captures patterns of educational attainment across age cohorts. For example, the proportion of people holding bachelor's, master's, or doctoral degrees differs between younger age groups and older age groups, reflecting historical shifts in access and in social norms.
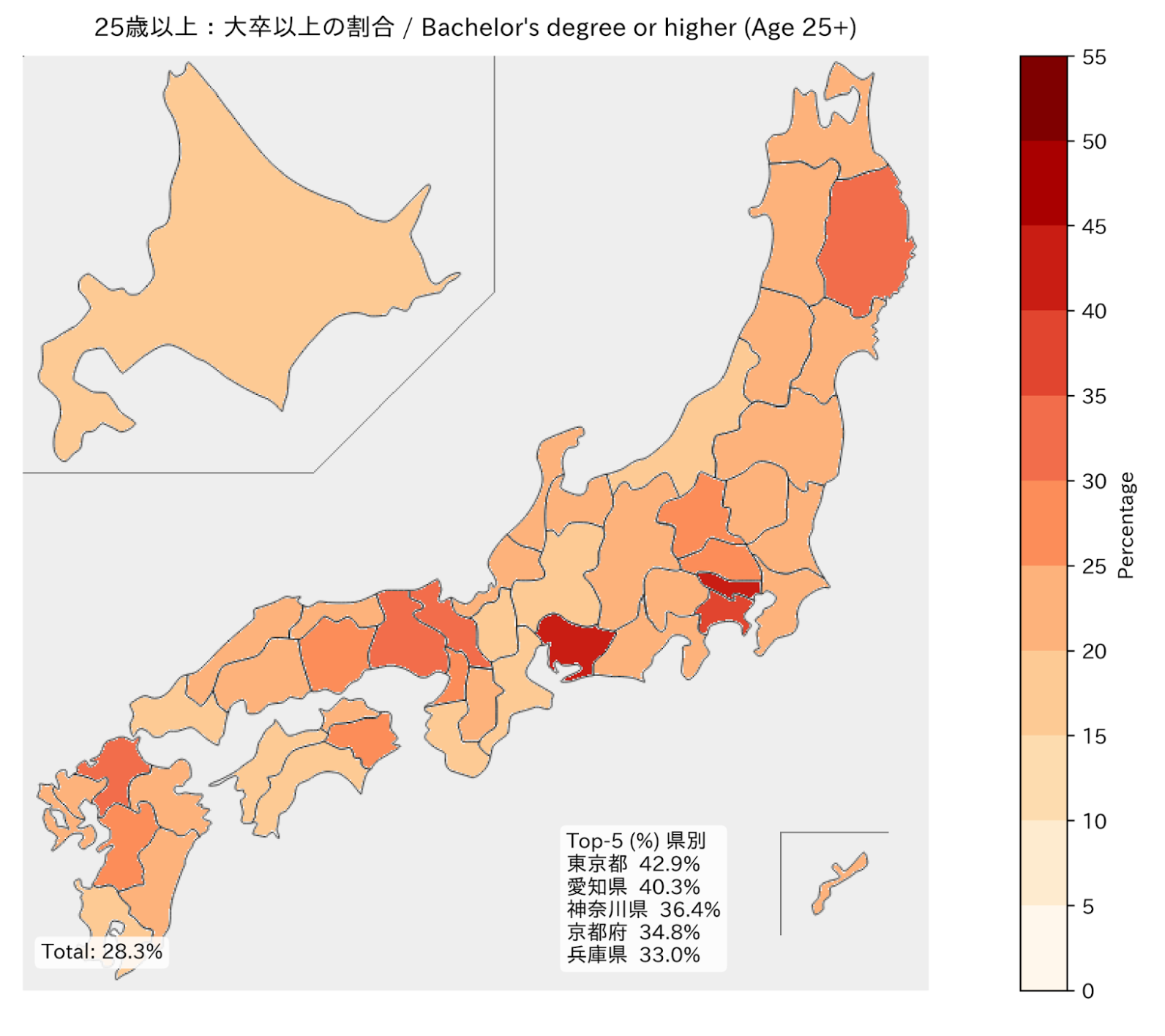
学歴の地理的特徴 (Geographic Intricacies of Education Attainment)
このデータセットの一部は、地理的要因が教育水準に影響を与え、ひいてはペルソナの記述にも反映されることを示しています。コロプレスマップは、各都道府県ごとに25歳以上の住民のうち学士号以上を取得している人の割合を示しています。私たちの検証では、いかなるLLMもこの精度のデータを生成することはできませんでした。
This slice of our dataset demonstrates how geography informs education and therefore persona descriptions. The choropleth map shows, for each prefecture, the share of residents ages 25 and older who hold at least a bachelor's degree. No LLM in our testing was able to generate data of this fidelity.
職業カテゴリ (Occupational Categories)
以下のツリーマップは、ペルソナの職業に関して本データセットが持つ豊かさを示しています。本データセットには、1,500を超える職業カテゴリが含まれており、さらに人口統計や地理的分布に基づいて補足されています。この図は、基本的な職業カテゴリのみを示しています。
The treemap below reflects the richness of our dataset with respect to professional occupations of personas. Represented in our dataset are over 1,500 occupation categories that are further informed by demographic and geographic distributions. This figure only shows basic occupation categories.

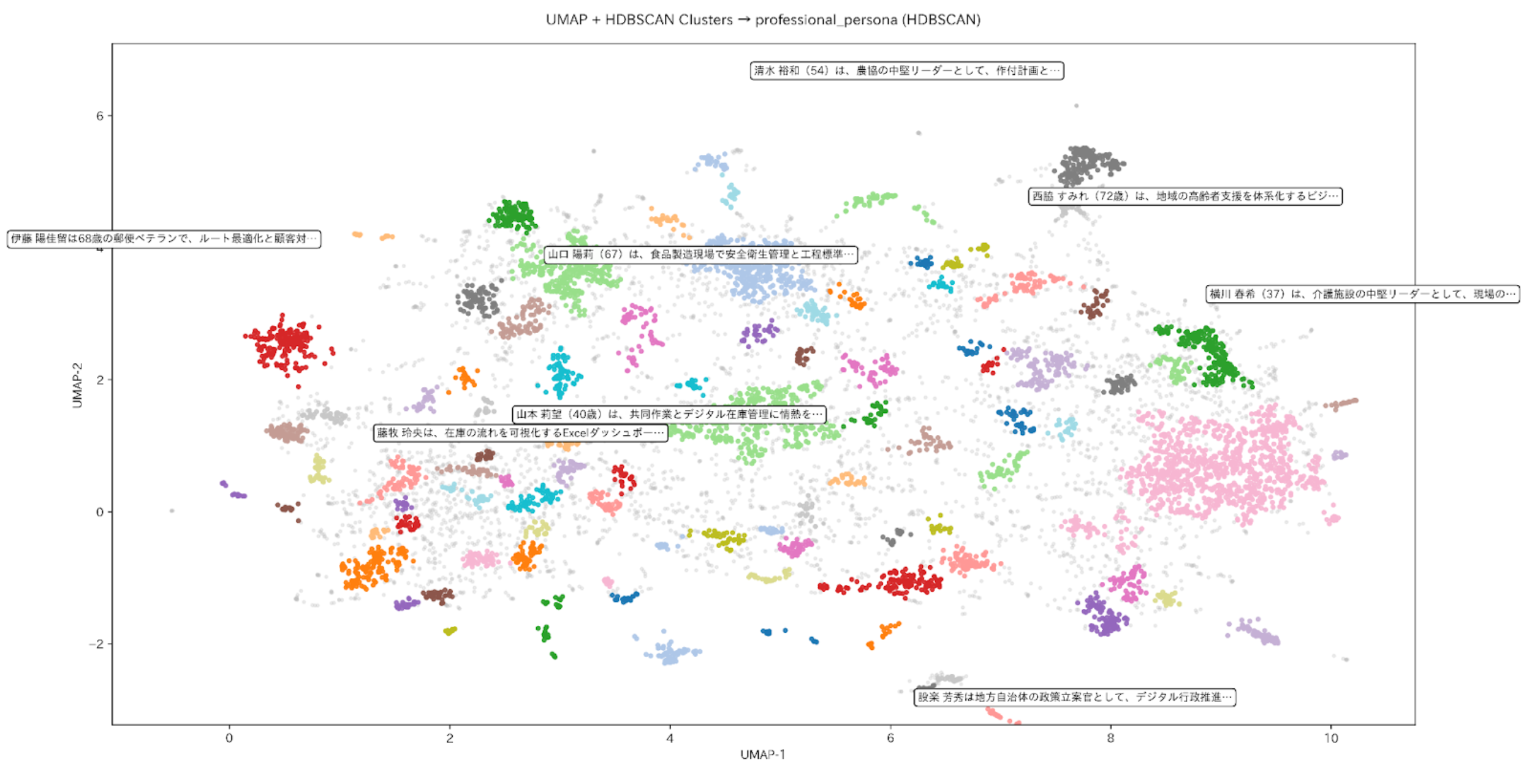
ペルソナの多様性 (Persona diversity)
上記の属性(およびその他多数の属性)は、最終的に生成される合成ペルソナの多様性に影響を与えます。例として、以下の分析では職業ペルソナの記述における多数のクラスターを示しています。これらのクラスターは、埋め込み表現をクラスタリングし、次元削減によって2次元に投影することで識別されています。
The attributes above (and many more) ultimately affect the diversity of the synthetic personas being generated. As an example, the analysis below highlights a multitude of clusters within professional persona descriptions. These clusters are identified by clustering embeddings and reducing dimensionality to 2D.
使い方 (How to use it)
以下のコードを実行することで、このデータセットを読み込むことができます。
You can load the dataset with the following lines of code.
from datasets import load_dataset
nemotron_personas = load_dataset("nvidia/Nemotron-Personas-Japan", "train")
データセット特性 (Dataset Characterization)
データ収集方法 (Data Collection Method)
- ハイブリッド: 人手・合成・自動 (Hybrid: Human, Synthetic, Automated)
ラベル方法 (Labeling Method)
- 該当なし (Not Applicable)
データセットフォーマット (Dataset Format)
- テキスト (Text)
データ規模 (Dataset Quantification)
- レコード数: 100万 (600万ペルソナ) (Record counts: 1M records (6M personas))
- ストレージサイズ (Total data storage): 1.73 GB
倫理的考慮事項 (Ethical Considerations):
NVIDIA は、信頼できる AI は共有すべき責任であると考えており、幅広い AI アプリケーションの開発を可能にするための方針や実践を確立しています。本モデルをダウンロードまたは利用する際は、利用規約に従うとともに、開発者は自社のモデルチームと協力し、本モデルが対象となる業界やユースケースの要件を満たし、想定外の不正使用に対応できるようにしてください。
セキュリティ上の脆弱性や NVIDIA AI に関する懸念事項は、こちらにご報告ください。
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal teams to ensure this dataset meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI concerns here.
引用 (Citation)
本データを利用する際には以下を引用してください。
If you find the data useful, please cite:
@software{nvidia/Nemotron-Personas-Japan,
author = {Fujita, Atsunori and Gong, Vincent and Ogushi, Masaya and Yamamoto, Kotaro and Suhara, Yoshi and Corneil, Dane and Meyer, Yev},
title = {{Nemotron-Personas-Japan}: Synthetic Personas Aligned to Real-World Distributions},
month = {September},
year = {2025},
url = {https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan}
}